Normalization in databases is the process of organizing data within tables to reduce redundancy and improve data integrity. Let me explain to you the steps that you follow in the normalization process in order:
Let us explain each stage of normalization using an example of an Invoice Table with the code for each stage.

Photo by Caspar Camille Rubin on Unsplash
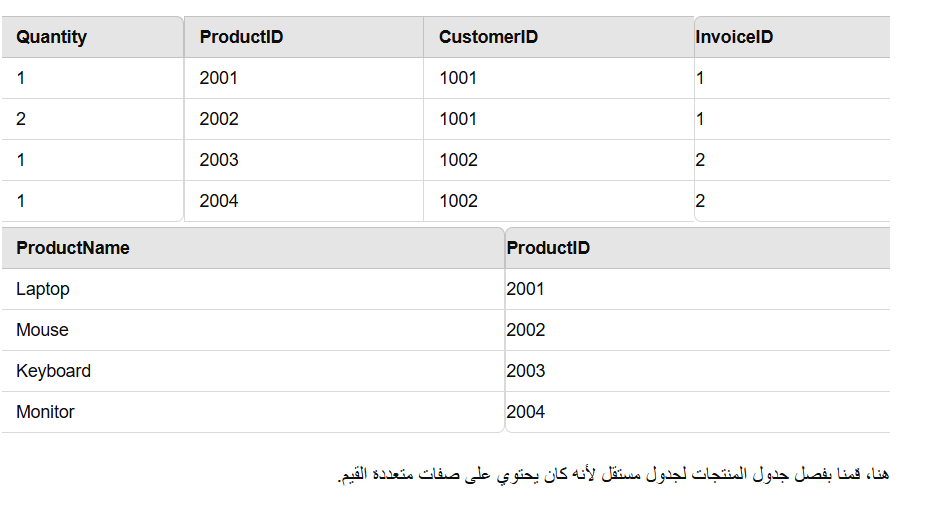
Zero Normal Form (0NF)
This is the first case in which the data could be more organized. This means that there is a repetition of data and duplicate data sets within the table.

2. First Normal Form (1NF)
In this case, we start by removing the repeating groups. The table here must have each column containing only one value for each record. This means that there is no room for you to put a list of values in one cell.
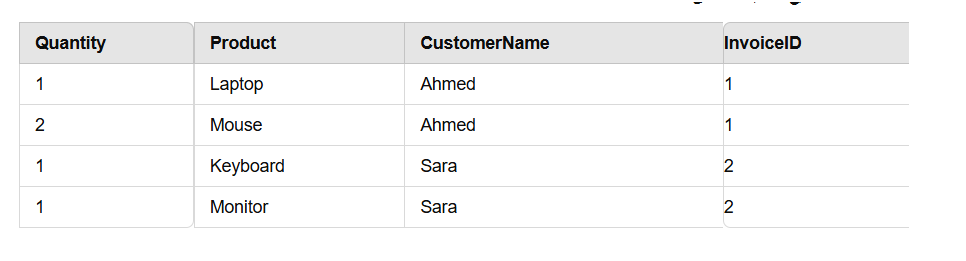
3. Second Normal Form (2NF)
Here we remove the partial dependencies. The table must be in the first form (1NF) first, and then we remove any non-key attribute column that is partially dependent on a part of the primary key only.
Here there are no partial dependencies because we are already in 1NF and “InvoiceID” is the only primary key.
But if the table had a composite key, for example if the primary key was (InvoiceID, Product), and some columns depended on only part of that key, we would have to split the table.
4. Third Normal Form (3NF)
Next, we remove the transitive dependencies. The table must be in the second form (2NF), and we remove any non-key column that depends on another non-key column, which in turn depends on the primary key.
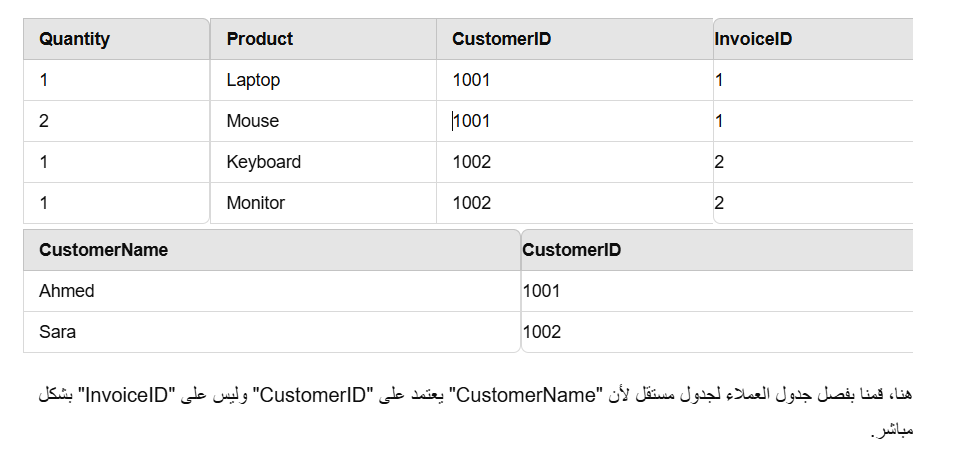
6. Fourth Normal Form (4NF)
Here we remove the multivalued attributes. That is, if we have an attribute that has more than one value for each record, we separate it into a separate table.